Il n'y a pas de réponse 100% noire ou blanche ici.
Habituellement Linux ne se fie pas aux noms de fichiers (et aux extensions de fichiers, c'est-à-dire la partie du nom de fichier après le dernier point habituel) et détermine plutôt le type de fichier en examinant les premiers octets de son contenu et en les comparant à une liste de fichiers connus. chiffres magiques .
Par exemple, tous les fichiers d'image Bitmap (généralement avec l'extension de nom .bmp ) doit commencer par les lettres BM dans leurs deux premiers octets. scripts dans la plupart des langages de script comme Bash, Python, Perl, AWK, etc. (en gros, tout ce qui traite les lignes commençant par # en tant que commentaire) peut contenir un shebang comme #!/bin/bash comme première ligne. Ce commentaire spécial indique au système avec quelle application ouvrir le fichier.
Normalement, le système d'exploitation se base sur le contenu du fichier et non sur son nom pour déterminer le type de fichier, mais affirmer que les extensions de fichier ne sont jamais nécessaires sous Linux n'est que la moitié de la vérité.
Les applications peuvent bien sûr mettre en œuvre leurs contrôles de fichiers comme elles le souhaitent, ce qui inclut la vérification du nom et de l'extension du fichier. Un exemple est l'œil de Gnome ( eog (visionneur d'images standard) qui détermine le format de l'image par l'extension du fichier et génère une erreur s'il ne correspond pas au contenu. La question de savoir s'il s'agit d'un bogue ou d'une fonctionnalité peut être discutée...
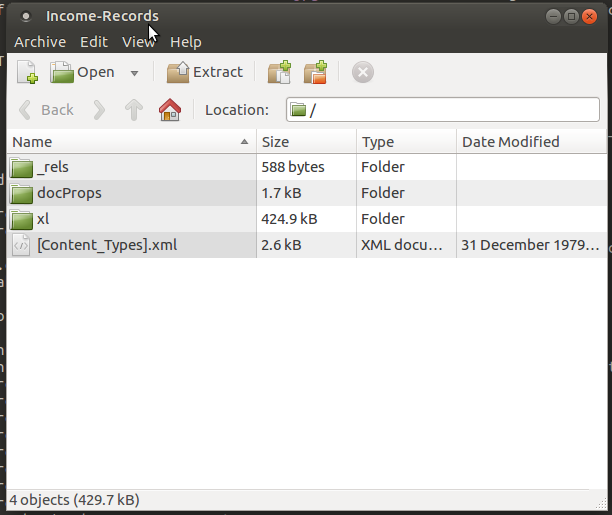
Cependant, même certaines parties du système d'exploitation s'appuient sur les extensions de nom de fichier, par exemple lors de l'analyse des fichiers de sources de votre logiciel dans le format /etc/apt/sources.list.d/ - seuls les fichiers avec l'extension *.list sont analysés, tous les autres sont ignorés. Elle n'est peut-être pas principalement utilisée pour déterminer le type de fichier mais plutôt pour activer/désactiver l'analyse de certains fichiers, mais il s'agit toujours d'une extension de fichier qui affecte la façon dont le système traite un fichier.
Et bien sûr, l'utilisateur humain tire le plus grand profit des extensions de fichiers, car elles rendent le type de fichier évident et permettent également de créer plusieurs fichiers avec le même nom de base et des extensions différentes, par exemple site.html , site.php , site.js , site.css etc. L'inconvénient est bien sûr que l'extension du fichier et le type de fichier/contenu réel ne doivent pas nécessairement correspondre.
De plus, il est nécessaire pour l'interopérabilité entre plates-formes, car par exemple, Windows ne saura pas quoi faire avec un fichier readme mais seulement un readme.txt .